Create Your Own File System | Part 1
In this series, you will learn to build your own file system using FUSE. Today I’ll focus on the theory behind file systems. The next post is about the implementation in FUSE using C.
Definitions
Be aware that the following definitions are simplified.
File: A file is a collection of bytes. These bytes can represent anything like text, image, video or audio. Files can have attributes like name, type or timestamp. Several operations are available for managing files: create, read, write, delete, etc.
Directory: A directory makes file management easier. On most modern operating systems, directories are just files that contain references to other files.
File System: A file system is an abstract layer that manages data on physical or virtual storage devices. It is used to store, retrieve and update data.
Ways of storing data on drives
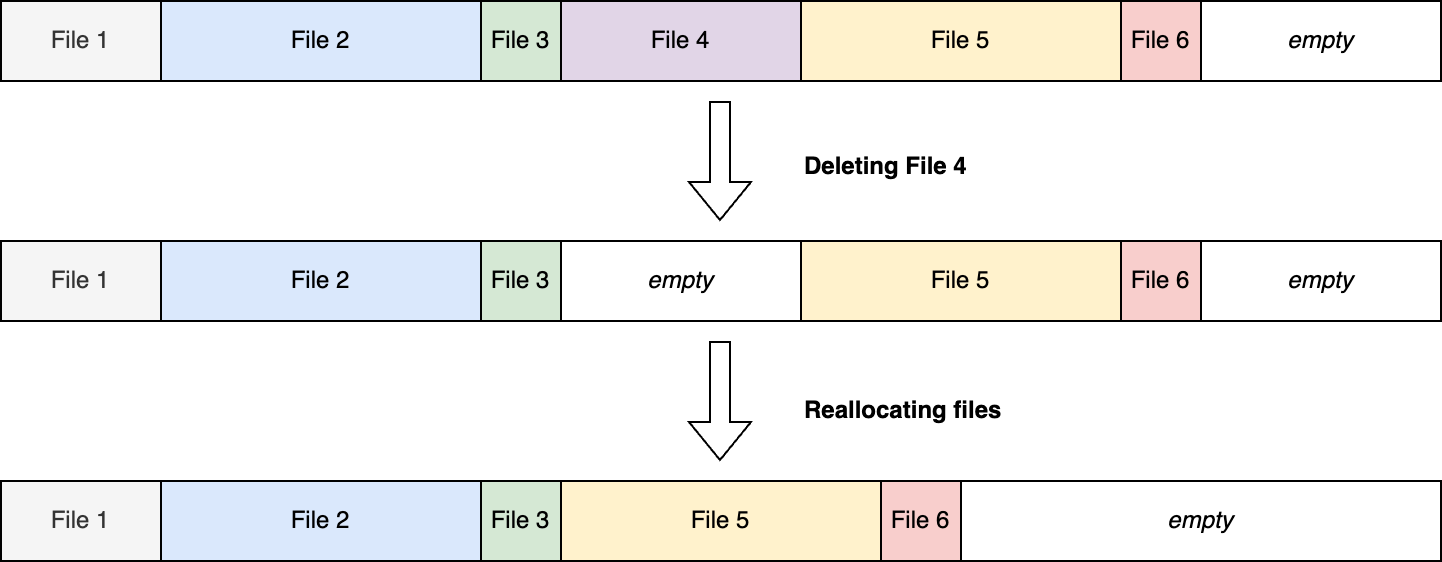
There are several ways of storing data on disk. The simplest way to store data is as a flat list with one file behind another. Such a system has several problems:
- When deleting a file, all files have to be reallocated to fill the new gap.
- When searching for a specific file, we have to loop through all files.
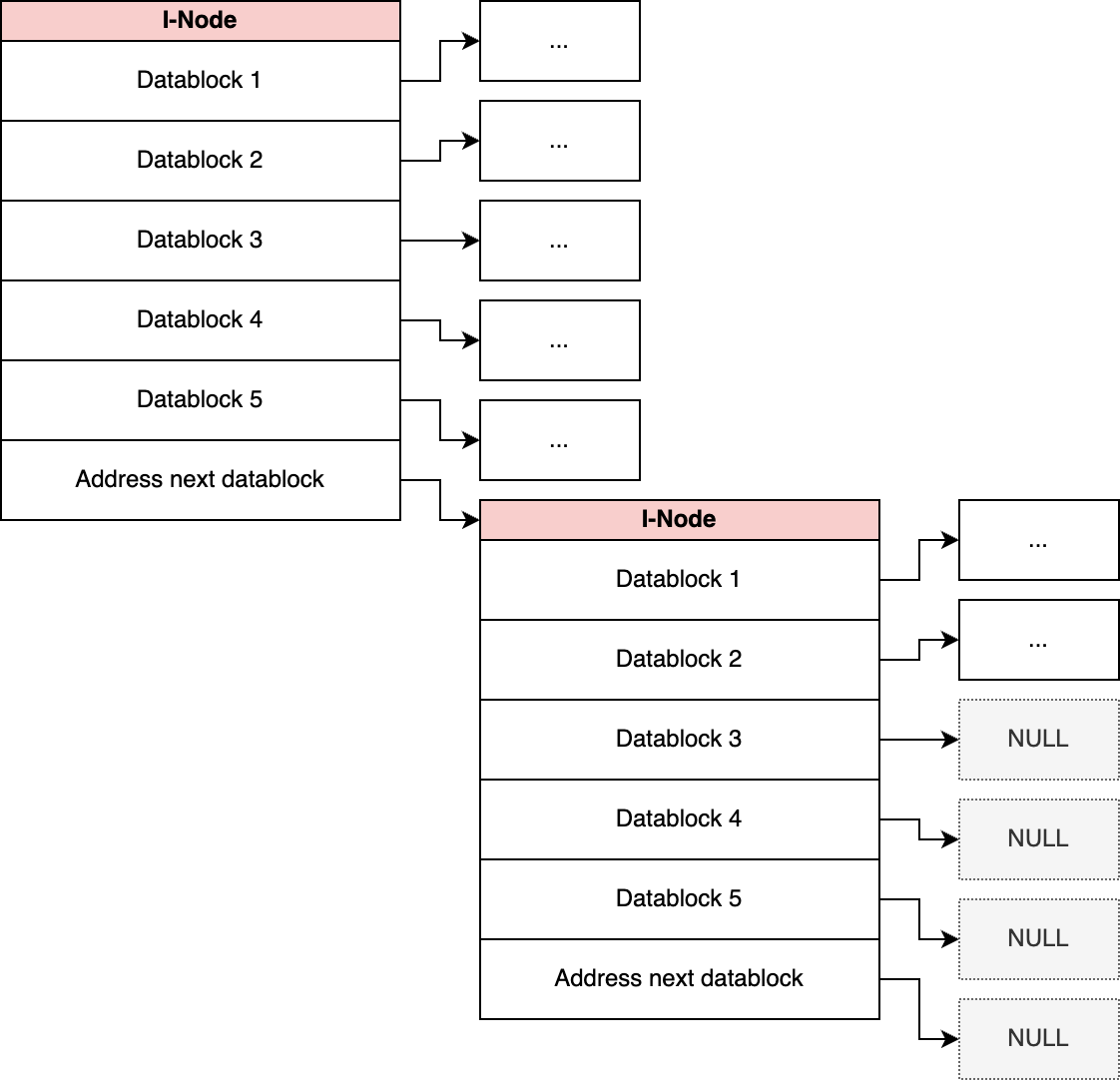
A better way is to store files as a linked list with specified block sizes. To do that, a file is divided into multiple blocks with a specified size (e.g. \(64\) bytes). Each block has a pointer that points to the address of the next data block. If it is the last bock of the file, the pointer is set to an invalid address (e.g. \(-1\)).

This resolves the first problem from the list above; however the second problem still persists. In addition, another problem arises:
- The address of the first data block of every file has to be stored in memory.
This problem seems to be small, but on systems with millions or billions of files, this problem is bigger than you might think. A system with \(2^{32}\) files with a block size of \(128\) bits need \(549.755.813.888\) addresses, which can be represented with \(39\) bits. To store \(2^{32}\) files, you need \(2^{32} \cdot 32 = 137.438.953.472\) bits, that is \(17,18\) gigabytes! The Apple File System (APFS) supports up to \(9.223.372.036.854.775.808\) files. It’s nearly impossible to store all the file addresses on memory.
That problem can be resolved with so-called I-Nodes. An I-Node is stored on the drive and represents a file or part of a file. When accessing a specific file, only the I-Node has to be loaded in memory.
FUSE
FUSE allows us file system developers to implement a file system without writing kernel extensions or even understanding the kernel. We develop our code in C and a FUSE library that communicates with the kernel. Developing a kernel extension is much more complex and platform-specific.
FUSE is available for Unix and Unix-like operating systems like Linux, macOS and FreeBSD.
Information for Macintosh users: You have to disable the System Integrity Protection (SIP) to use FUSE. To avoid doing that, I recommend using a virtual Linux or macOS machine.
A list of FUSE file systems is available in the FUSE Wiki. Take a look at the official documentation if you’re interested. A list of all FUSE functions is available here (not all FUSE functions are required).
Simple 64 kb Flat File System (S64FFS)
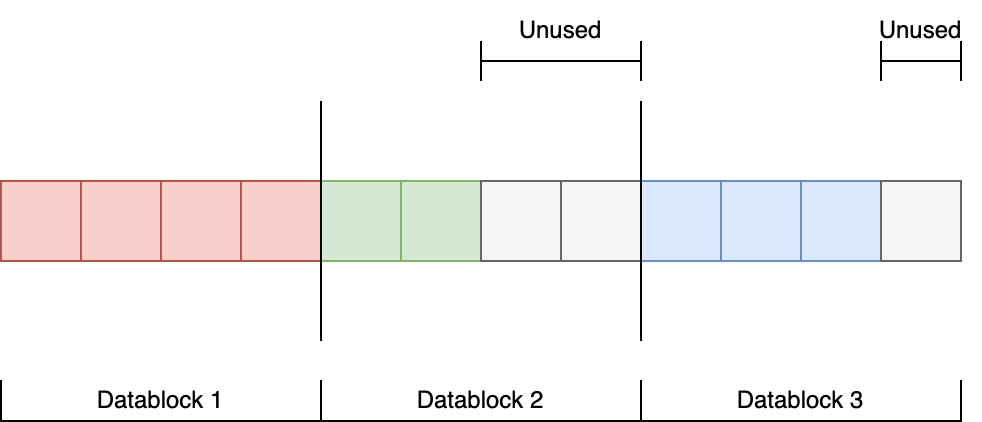
I’ve developed a simple file system for educational purposes, called S64FFS. It allows storing \(64\) files with a size of \(1\) kb each (excluding file attributes).
The drive is divided into two sections:
- Drive attributes: name, number of files and free space
- Data blocks
I solved the problem of storing the address of the first data block of every file by using a fixed size of \(64\) files.
However, by that, the number of files is limited, and storage is wasted when a file is smaller than \(1\) kb.
Larger files are not supported. Unused data blocks are marked with a reserved name (e.g. \0).
Drive Attributes
The Drive attributes contain the following information with the following sizes:
- name:
30bytes (29 characters excluding the null terminator) - number of files:
1byte (static value of64) - free space:
1byte
Because the drive attributes have a fixed size of 32 bytes, SFFS-64 needs \(65.536 + 32 = 65.568\) bytes of storage.
Data Blocks
A data block contains 1024 bytes (including the file attributes).
The file attributes are:
- file name:
32bytes - file size:
2bytes - owner:
22bytes - creation date:
4bytes - creation time:
4bytes - data:
960bytes
This definition limits the net file size to 960 bytes.
Data Manipulation on S64FFS
In the next post, we will implement the following functions:
getattr: get file attributes (similar tostatin Unix)readdir: lists the content of our drive (similar tolsin Unix)open: opens a file- checks file existence and access rights
read: reads a file into a bufferwrite: writes a buffer into a filecreate: creates a new fileunlink: deletes a file
But before we start with the implementation, we have to understand how these functions work.
Function getattr
If you run stat or ls -l in Unix, you get information/metadata about a specified file or directory.
The output of ls -l in my home directory looks like this:
gregor@Gregors-MacBook-Pro ~ % ls -l
total 0
drwxr-xr-x@ 4 gregor staff 128 Mar 14 07:21 Applications
drwx------@ 14 gregor staff 448 Mar 14 14:10 Desktop
drwxr-xr-x@ 35 gregor staff 1120 Mar 14 11:30 Developer
drwx------+ 15 gregor staff 480 Mar 4 13:25 Documents
drwx------+ 6 gregor staff 192 Mar 14 13:28 Downloads
drwx------@ 98 gregor staff 3136 Mar 14 14:08 Library
drwx------ 4 gregor staff 128 Mar 4 12:46 Movies
drwx------+ 4 gregor staff 128 Mar 4 15:23 Music
drwx------+ 5 gregor staff 160 Mar 5 14:51 Pictures
drwxr-xr-x+ 4 gregor staff 128 Mar 4 11:00 Public
From left to right, the columns represent:
- file permissions
- number of hard links (references to the file)
- owner
- group
- file size in bytes
- last modification date
- last modification time
- file name
For now, we focus on owner, last modification date and time, file name and file size. These are the attributes we have defined above.
With stats you can get the metadata of a file.
You can run it with stat <path_to_file>.
The output looks like that:
16777233 835959 -rw-r--r-- 1 gregor staff 0 154539 "Mar 8 11:02:35 2025" "May 31 20:09:08 2024" "Mar 4 12:53:36 2025" "May 31 20:09:08 2024" 4096 304 0 Banner.png
The output of stat can differ based on your shell.
On macOS the format is the following:
- device (
st_dev):16777233 - file’s I-Node number (
st_ino):835959 - file type and permission (
st_mode):-rw-r--r-- - user ID and group ID (
st_uid,st_gid):gregor staff - device number (
st_rdev):0 - size of the file in bytes (
st_size):154539 - time of last access (
st_atime):"Mar 8 11:02:35 2025" - time of last modification (
st_mtime):"May 31 20:09:08 2024" - last change of I-Node (
st_ctime):"Mar 4 12:53:36 2025" - birth time of the I-Node (
st_birthtime):"May 31 20:09:08 2024" - optimal file system I/O operation block size (
st_blksize):4096 - number of blocks allocated for the specified file (
st_blocks):304 - flags of the file:
0 - file name:
myfile.png
This information is really interesting for us file system developers.
From st_size and st_blocks we can calculate the size of the blocks: \(\frac{154539}{304} \approx 512 \, \text{bytes}\).
Function readdir
The readdir-function writes the content of a specified directory (we only have one “directory”) into a buffer.
On Unix you can see the content of a directory using ls <path_to_directory>.
An example output of ls in my home directory:
gregor@Gregors-MacBook-Pro ~ % ls
Applications Developer Downloads Movies Pictures
Desktop Documents Library Music Public
Function open
This function checks if a specified file exists.
Note that the open command on Unix is not the same, because it returns a file descriptor, while open checks if the specified file exists.
Function read and write
When you already used C, you know the read-function that reads a file into a specified buffer.
The read-function of S64FFS is similar; however it already gives the opportunity to set an offset that you don’t have to use lseek.
write will work the same way as read but the other way around.
Function create and unlink
create creates the specified file and opens it afterward.
In C, you can create files using the open-function together with O_CREAT;
however FUSE separates opening and creating files.
To delete files, I implemented a function called unlink.
Conclusion
There is more than one way to store data on a drive. You can store files as a flat list, as a linked list or using I-Nodes. All these methods have their advantages and disadvantages. To make the file system development easier, we use FUSE. We’ve learned about the basic FUSE functions and the S64FFS file system.
In the next post, we will implement the S64FFS file system.
See you in the next post! :-)